80/TCP 8s
$ curl 10.101.106.248:80
Welcome to nginx!
Welcome to nginx!
If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.
For online documentation and support please refer to
nginx.org.
Commercial support is available at
nginx.com.
Thank you for using nginx.
```
### 8. Volume & Storage
如前所述,在设计容器时并没有考虑到持久存储,特别是当存储跨越多个节点时。Kubernetes介绍了一些解决方案,但请注意,这些解决方案并没有自动消除使用容器管理存储的所有复杂性。\
集装箱已经有了安装卷的概念,但由于我们没有直接使用集装箱,Kubernetes将卷作为Pod的一部分,就像集装箱一样。\
下面是一个`hostPath`卷挂载的例子,类似于Docker引入的主机挂载:
```
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# directory location on host
path: /data
# this field is optional
type: Directory
```
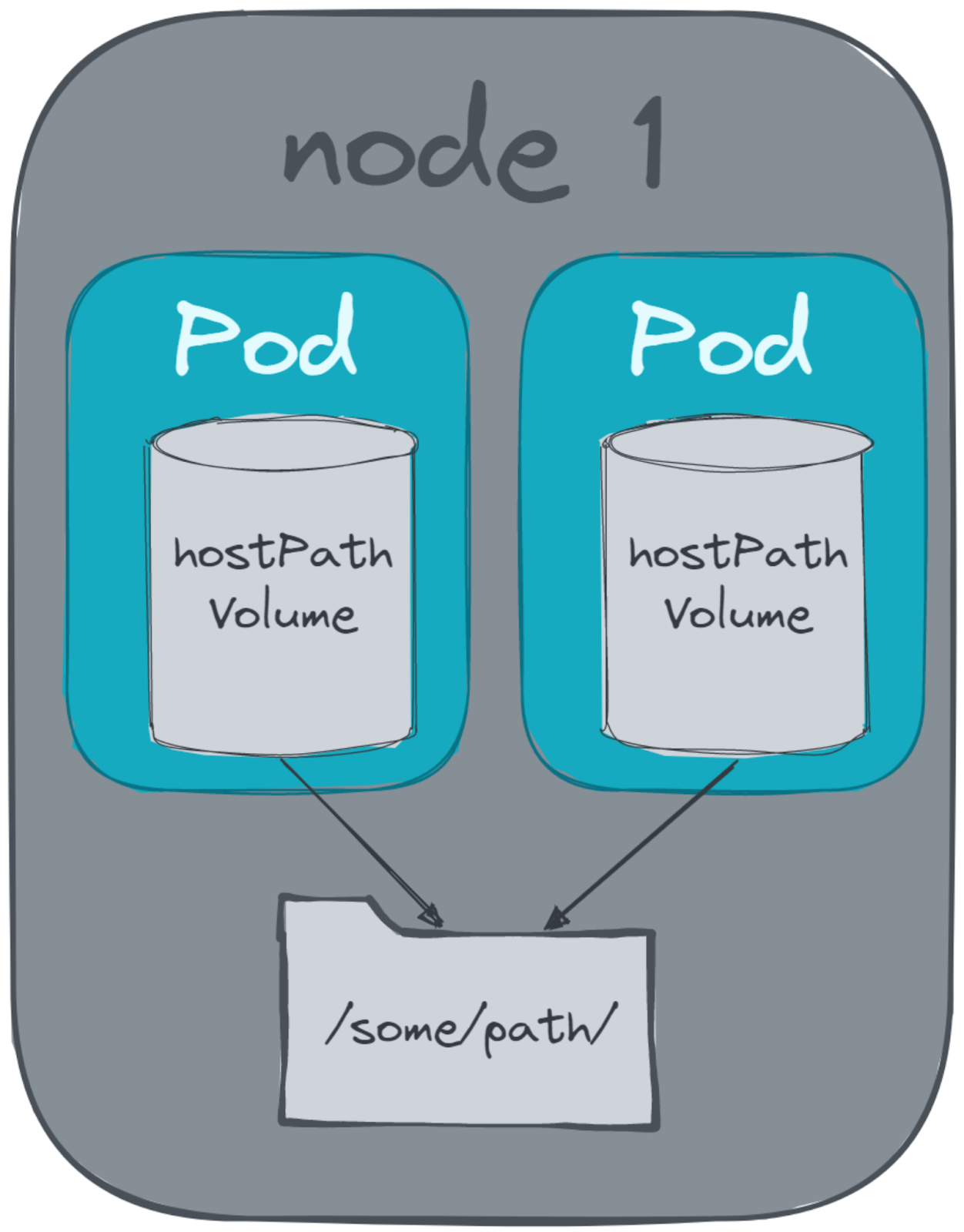\
卷允许在同一个Pod中的多个容器之间共享数据。当您想要使用侧车模式时,这个概念允许极大的灵活性。它们的第二个用途是在Pod崩溃并在同一节点上重新启动时防止数据丢失。pod以干净的状态启动,但所有数据会丢失,除非写入卷。\
不幸的是,包含多个服务器的集群环境在持久性存储方面需要更多的灵活性。根据环境的不同,我们可以使用像[Amazon EBS](https://aws.amazon.com/ebs/)、[谷歌Persistent Disks](https://cloud.google.com/persistent-disk)、[Azure Disk storage](https://azure.microsoft.com/en-us/services/storage/disks/)这样的云块存储,也可以使用像[Ceph](https://ceph.io/en/)、[GlusterFS](https://www.gluster.org/)这样的存储系统或更传统的系统,比如NFS。\
这些只是Kubernetes中可以使用的存储的几个例子。为了让用户体验更加统一,Kubernetes使用了容器存储接口CSI (Container Storage Interface),它允许存储供应商编写一个可以在Kubernetes中使用的插件(存储驱动程序)。
为了使用这个抽象,我们还有两个可以使用的对象:
* PersistentVolumes (PV)\
存储片的抽象描述。对象配置包含卷的类型、卷大小、访问模式和唯一标识符以及如何挂载它的信息。
* PersistentVolumeClaims (PVC)\
用户对存储的请求。如果集群有多个持久化卷,用户可以创建一个PVC,根据用户的需要预留一个持久化卷。
```
apiVersion: v1
kind: PersistentVolume
metadata:
name: test-pv
spec:
capacity:
storage: 50Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
csi:
driver: ebs.csi.aws.com
volumeHandle: vol-05786ec9ec9526b67
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ebs-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi
---
apiVersion: v1
kind: Pod
metadata:
name: app
spec:
containers:
- name: app
image: centos
command: ["/bin/sh"]
args:
["-c", "while true; do echo $(date -u) >> /data/out.txt; sleep 5; done"]
volumeMounts:
- name: persistent-storage
mountPath: /data
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: ebs-claim
```
这个例子展示了一个`PersistentVolume`,它使用了一个使用CSI驱动程序实现的AWS EBS卷。在配置了PersistentVolume之后,开发人员可以使用PersistentVolumeClaim来预留它。最后一步是在Pod中使用PVC作为卷,就像我们之前看到的hostPath示例一样。\
可以直接在Kubernetes中操作存储集群。像[Rook](https://rook.io/)这样的项目提供云本地存储业务编排,并与经过实战测试的存储解决方案(如Ceph)集成。\
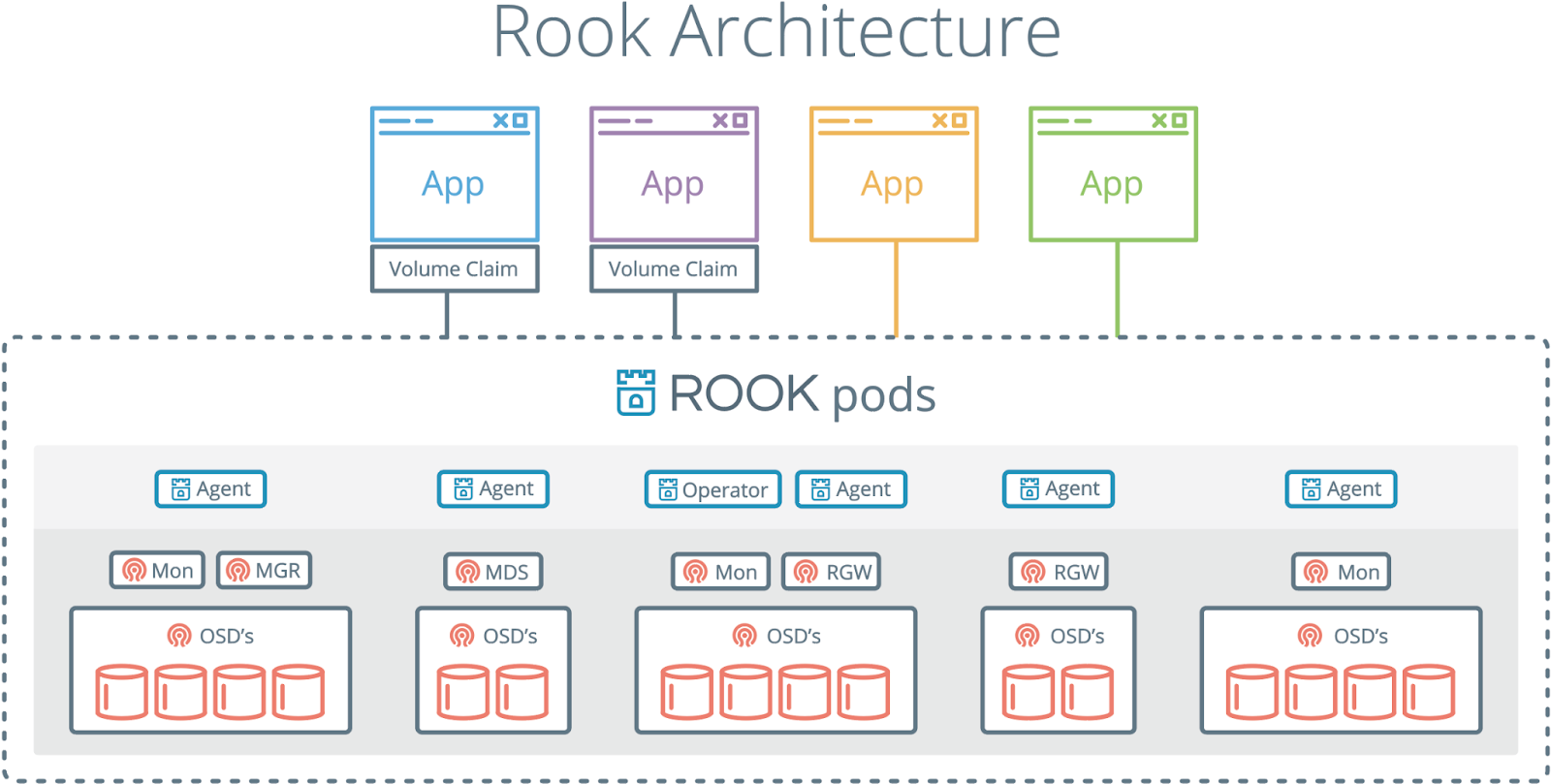
Rook架构,[从Rook文档中检索](https://rook.io/docs/rook/v1.7/ceph-storage.html)
### 9. 配置对象
[12因素应用程序建议将配置存储在环境](https://12factor.net/config)中。但这到底是什么意思呢?运行应用程序需要的不仅仅是应用程序代码和一些库。应用程序有配置文件,连接到其他服务、数据库、存储系统或缓存,这需要像连接字符串这样的配置。\
将配置直接合并到容器构建中被认为是不好的做法。任何配置更改都需要重新构建整个映像,并重新部署整个容器或吊舱。当使用多个环境(开发、登台、生产)并为每个环境构建映像时,这个问题只会变得更糟。12因素应用程序更详细地解释了这个问题:[Dev/prod奇偶性](https://12factor.net/dev-prod-parity)。\
在Kubernetes中,这个问题是通过使用ConfigMap将配置从Pods中解耦来解决的。ConfigMaps可用于将整个配置文件或变量存储为键-值对。有两种可能的方式使用ConfigMap:
* 将ConfigMap挂载为Pod中的卷
* 将ConfigMap中的变量映射到Pod中的环境变量。
下面是一个包含nginx配置的ConfigMap示例:
```
apiVersion: v1
kind: ConfigMap
metadata:
name: nginx-conf
data:
nginx.conf: |
user nginx;
worker_processes 3;
error_log /var/log/nginx/error.log;
...
server {
listen 80;
server_name _;
location / {
root html;
index index.html index.htm; } } }
```
一旦ConfigMap被创建,你就可以在Pod中使用它:
```
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.19
ports:
- containerPort: 80
volumeMounts:
- mountPath: /etc/nginx
name: nginx-conf
volumes:
- name: nginx-conf
configMap:
name: nginx-conf
```
从一开始,Kubernetes也提供了一个对象来存储敏感信息,如密码、密钥或其他凭证。这些对象被称为[Secrets](https://kubernetes.io/zh/docs/concepts/configuration/secret/#using-secrets)。秘密与ConfigMaps非常相关,基本上它们唯一的区别是秘密是base64编码的。\
关于使用“秘密”的风险,人们一直在争论不休,因为“秘密”(与名称相反)并不被认为是安全的。在原生云环境中,已经出现了专门创建的秘密管理工具,它们可以很好地与Kubernetes集成。[HashiCorp Vault](https://www.vaultproject.io/)就是一个例子。
### 10. Autoscaling
自动伸缩机制
* [Horizontal Pod Autoscaler (HPA)](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/)\
Horizontal Pod Autoscaler (HPA)是Kubernetes中最常用的自动定标器。HPA可以监视deployments或ReplicaSets,并在达到某个阈值时增加副本的数量。成像Pod可以使用500MiB的内存,并且您配置了80%的阈值。如果利用率超过400MiB(80%),将调度第二个Pod。现在您的容量为1000MiB。如果使用了800MiB,将调度第三个Pod,以此类推。
* [Cluster Autoscaler](https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler)\
当然,如果集群容量是固定的,那么启动越来越多的pod副本是没有意义的。如果需求增加,Cluster Autoscaler可以向集群添加新的工作节点。集群自动伸缩器与水平自动伸缩器协同工作。
* [Vertical Pod Autoscaler](https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler)\
Vertical Pod Autoscaler 相对较新,允许吊舱动态增加资源请求和限制。如前所述,垂直扩展受到节点容量的限制。
不幸的是,Kubernetes的(水平)自动伸缩是无法开箱即用的,需要安装一个名为[metrics-server](https://github.com/kubernetes-sigs/metrics-server)的附加组件。
但是,用Kubernetes Metrics api的[Prometheus Adapter](https://github.com/kubernetes-sigs/prometheus-adapter)替换度量服务器是可能的。prometheus-adapter允许您在Kubernetes中使用自定义指标,并根据系统上的请求或用户数量等因素进行放大或缩小。\
像[KEDA](https://keda.sh/)这样的项目可以根据外部系统触发的事件来扩展Kubernetes工作负载,而不是仅仅依赖于指标。KEDA是基于kubernetes的事件驱动自动scaler的缩写,于2019年作为微软和红帽公司的合作伙伴启动。与HPA类似,KEDA可以扩展部署、复制集、pod等,还可以扩展Kubernetes作业等其他对象。通过大量现成的扩展器的选择,KEDA可以扩展到特殊的触发器,比如数据库查询,甚至Kubernetes集群中pod的数量。
交互式教程-缩放您的应用程序\
在交互式教程的第五部分:运行应用程序的多个实例中,你可以学习[如何手动扩展应用程序](https://kubernetes.io/docs/tutorials/kubernetes-basics/scale/scale-intro/)。
### 11. Additional Resources
Learn more about…
Differences between Containers and Pods
* [What are Kubernetes Pods Anyway?](https://www.ianlewis.org/en/what-are-kubernetes-pods-anyway), by Ian Lewis (2017)
* [Containers vs. Pods](https://iximiuz.com/en/posts/containers-vs-pods/) - Taking a Deeper Look, by Ivan Velichko (2021)
kubectl tips & tricks
* [kubectl Cheat Sheet](https://kubernetes.io/docs/reference/kubectl/cheatsheet/)
Storage and CSI in Kubernetes
* [Container Storage Interface (CSI) for Kubernetes GA](https://kubernetes.io/blog/2019/01/15/container-storage-interface-ga/), by Saad Ali\
(2019)
* [Kubernetes Storage: Ephemeral Inline Volumes, Volume Cloning,Snapshots and more!](https://www.inovex.de/de/blog/kubernetes-storage-volume-cloning-ephemeral-inline-volumes-snapshots/), by Henning Eggers (2020)
Autoscaling in Kubernetes
* [Architecting Kubernetes clusters - choosing the best autoscaling strategy](https://learnk8s.io/kubernetes-autoscaling-strategies), by Daniele Polencic (2021)
***
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://ghostwritten.gitbook.io/kubernetes-exam-in-action/kcna-kao-shi/kcna-4kubernetes-shi-jian.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.