KCNA 6:监控与探测
1. 简介
术语cloud native observability听起来像是另一个用来推销新工具的流行词。这可能是事实,我们有很多新工具出现来解决监控容器基础设施的问题。
服务器的常规监控可能包括收集系统的基本指标,如CPU和内存资源使用情况,以及进程和操作系统的日志记录。微服务体系结构面临的一个新挑战是监视在分布式系统中移动的请求。这一原则称为跟踪,在响应请求时涉及大量服务时特别有用。
在本章中,我们将学习容器基础设施如何仍然依赖于收集度量和日志,但对需求的改变相当大。它更多地关注网络问题,如延迟、吞吐量、请求重试或应用程序启动时间,而分布式系统中大量的指标、日志和跟踪需要采用不同的方法来管理这些系统。
2. 学习目标
在本章结束时,你应该能够:
解释为什么observability是云计算的关键学科。
讨论度量、日志和跟踪。
了解如何显示容器化应用程序的日志。
解释如何使用Prometheus收集和存储指标。
了解如何优化云成本。
3. Observability
可观察性通常与监视是同义词,但监视只是云本地可观察性的一个子类别,不能充分发挥其作用。可观察性一词与处理动态系统行为的控制理论密切相关。从本质上说,控制理论描述了如何测量系统的外部输出来操纵系统的行为。 一个常见的例子是汽车的巡航控制系统。你设定汽车的期望速度,这个速度可以被一个人通过速度计不断测量。为了在变化的条件下保持速度,例如开车上山时,电动机的功率必须调整以保持速度。 在IT系统中,同样的原则可以应用于自动伸缩。您可以设置所需的系统利用率,并根据系统负载触发伸缩事件。 以这种方式自动化系统可能非常具有挑战性,而且不是可观察性最重要的用法。当我们处理容器编排和微服务时,最大的挑战是跟踪系统,它们如何相互交互,以及它们在负载或错误状态下的行为。 可观察性应该回答以下问题:
系统是稳定的还是在被操纵时改变了状态?
系统对变化是否敏感,例如某些服务是否有高延迟?
系统中的某些指标是否超出了它们的极限?
为什么对系统的请求失败?
系统是否存在瓶颈?
可观察性的更高目标是允许对收集到的数据进行分析。这有助于更好地理解系统并对错误状态作出反应。这种技术方面的东西与现代敏捷软件开发密切相关,后者也使用反馈循环,在这种循环中,您可以分析软件的行为,并根据结果不断地对其进行调整。
4. 遥测(Telemetry)
遥测术这个术语有希腊词根,意思是远程或距离(遥测)和测量(测量)。测量和收集数据点,然后将其转移到另一个系统,当然,并不只是云本地系统,甚至it系统。一个很好的例子是一个带有数据记录器的气象站,它可以在某一点测量温度、湿度、风速等,然后将数据传输到另一个系统,该系统可以处理和显示这些数据。 在容器系统中,每个应用程序都应该内置生成信息数据的工具,然后在一个集中的系统中收集和传输信息数据。这些数据可以分为三类。
logs 当出现错误、警告或调试信息时,这些消息从应用程序中发出。一个简单的日志条目可以是应用程序执行的特定任务的开始和结束。
metrics metrics是一段时间内进行的定量度量。这可能是请求数或错误率。
traces 它们在请求通过系统时跟踪请求的进程。跟踪是在分布式系统中使用的,它可以提供关于服务何时处理请求以及它花了多长时间的信息。
许多传统的系统甚至不需要费心将数据(如日志)传输到一个集中的系统,要查看日志,您必须连接到系统并直接从文件中读取。 在具有数百或数千个服务的分布式系统中,这将意味着大量的工作和故障排除将非常耗时。
5. Logging
今天,应用程序框架和编程语言内置了大量的日志工具,这使得根据日志消息的严重程度将不同的日志级别记录到文件中非常容易。 Python编程语言的文档提供了以下示例:
Unix和Linux程序提供三个I/O流,其中两个用于从容器输出日志:
标准输入(stdin):向程序输入,例如通过键盘输入。
标准输出(stdout):程序写入屏幕的输出。
标准错误(stderr):程序写入屏幕的错误
docker、kubectl或podman等命令行工具提供了一个命令来显示容器化进程的日志,如果您让它们直接记录到控制台或/dev/stdout和/dev/stderr. 查看容器nginx的日志信息:
如果要将日志实时流化,可以在命令中添加-f参数。Kubernetes通过kubectl命令行工具提供了相同的功能。kubectl logs命令的文档提供
这些方法允许与单个容器进行直接交互。但是为了管理大量的数据,需要将这些日志发送到存储这些日志的系统。可以使用不同的方式发送日志:
Node-level logging 收集日志的最有效方式。管理员配置日志传送工具,用于收集日志并将其传送到中央存储区。
Logging via sidecar container 该应用程序有一个sidecar容器,用于收集日志并将其发送到一个中央存储库。
Application-level logging 应用程序将日志直接推送到中央存储区。虽然这在一开始看起来非常方便,但它需要在集群中运行的每个应用程序中配置日志适配器。
有几种工具可以用来传送和存储日志。前两个方法可以通过fluentd或filebeat这样的工具来实现。
存储日志的常用选择是OpenSearch或Grafana Loki。要查找更多的数据存储,可以访问有关可能的日志目标的fluentd文档。 为了使日志易于处理和搜索,请确保您以结构化格式(如JSON)登录,而不是纯文本。主要的云供应商提供了关于结构化日志的重要性以及如何实现它的很好的文档:
6. Prometheus
Prometheus是一个开源监控系统,最初由SoundCloud开发,并于2016年成为CNCF托管的第二个项目。随着时间的推移,它成为了一个非常流行的监控解决方案,现在是一个标准工具,在Kubernetes和容器生态系统中集成得特别好。 Prometheus可以收集应用程序和服务器作为时间序列数据发出的指标——这些是非常简单的数据集,包括时间戳、标签和度量本身。普罗米修斯数据模型提供了四个核心指标:
Counter:增加的值,如请求数或错误数
Gauge:增加或减少的值,如内存大小
Histogram:一个观察样本,如请求持续时间或响应大小
Summary:类似于直方图,但也提供了观察的总数。
要公开这些指标,应用程序可以在/指标下公开HTTP端点,而不是自己实现它。你可以使用现有的客户端库:
go
Java或Scala
Python
Ruby
您还可以使用Prometheus文档中列出的众多非官方客户端库之一。 暴露的数据可能是这样的
Prometheus内置了对Kubernetes的支持,可以配置为自动发现集群中的所有服务,并在定义的时间间隔内收集度量数据,以将它们保存在时间序列数据库中。 为了查询存储在时间序列数据库中的数据,Prometheus提供了一种名为Prometheus query language (Prometheus query language)的查询语言。用户可以使用PromQL实时选择和聚合数据,并在内置的Prometheus用户界面中查看数据,该界面提供简单的图形或表格视图。 以下是一些来自普罗米修斯文档的例子:
或者给出一个随时间变化的速率的样本函数
您可以使用这些函数来获得某个值如何随时间增加或减少的指示。这将有助于分析应用程序的错误或预测失败。 当然,只有使用所收集的数据时,监视才有意义。Prometheus最常用的伙伴是Grafana,它可以根据收集到的指标构建仪表板。您可以将Grafana用于更多的数据源,而不仅仅是Prometheus,尽管它是最常用的一个。
 Grafana仪表盘,从Grafana网站检索
Grafana仪表盘,从Grafana网站检索
Prometheus生态系统的另一个工具是Alertmanager。Prometheus服务器本身允许您在某些指标达到或超过阈值时配置警报。当警报触发时,Alertmanager可以向您最喜欢的持久聊天工具、电子邮件或专门的工具发送通知,这些工具是为警报和随叫随到管理。 以下是《Prometheus》中警告规则的一个例子:
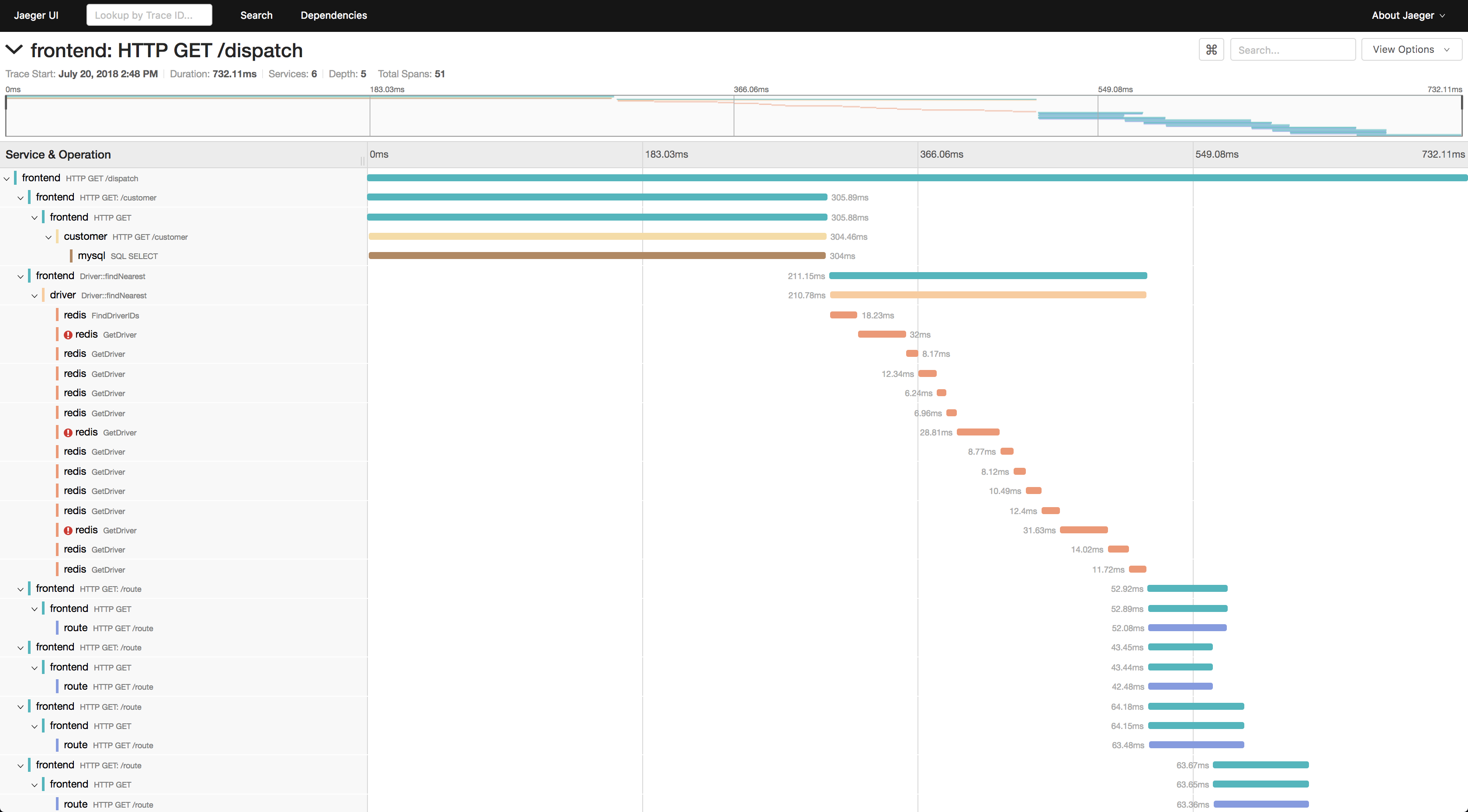
7. Tracing
使用度量集合进行日志记录和监视并不是特别新的方法。(分布式)跟踪就不能这么说了。度量和日志非常重要,可以很好地概述各个服务,但要理解在微服务体系结构中如何处理请求,Tracing可以很好地发挥作用。 Tracing描述了在请求通过服务时对请求的跟踪。跟踪由多个工作单元组成,这些工作单元表示在请求传递系统时发生的不同事件。每个应用程序都可以为跟踪贡献一个跨度,其中可以包括开始和结束时间、名称、标记或日志消息等信息。 这些 traces可以在Jaeger这样的跟踪系统中存储和分析。  追踪细节,从机Jaeger website上找到的 虽然跟踪是一种面向云本地环境的新技术和方法,但在标准化方面又出现了问题。2019年,OpenTracing和OpenCensus项目合并形成OpenTelemetry项目,该项目现在也是CNCF项目。 OpenTelemetry是一组应用程序编程接口(api)、软件开发工具包(sdk)和工具,可用于集成度量、协议等遥测技术,特别是跟踪应用程序和基础设施。OpenTelemetry客户端可用于将遥测数据以标准化格式导出到Jaeger等中央平台。现有的工具可以在OpenTelemetry文档中找到。
追踪细节,从机Jaeger website上找到的 虽然跟踪是一种面向云本地环境的新技术和方法,但在标准化方面又出现了问题。2019年,OpenTracing和OpenCensus项目合并形成OpenTelemetry项目,该项目现在也是CNCF项目。 OpenTelemetry是一组应用程序编程接口(api)、软件开发工具包(sdk)和工具,可用于集成度量、协议等遥测技术,特别是跟踪应用程序和基础设施。OpenTelemetry客户端可用于将遥测数据以标准化格式导出到Jaeger等中央平台。现有的工具可以在OpenTelemetry文档中找到。
{kind=link}
8. 成本管理(Cost Management)
云计算的可能性允许我们从理论上无限的资源池中提取资源,并且只在真正需要的时候为它们付费。由于云服务提供商提供的服务不是公益性的,因此在云计算中,成本优化的关键是分析什么是真正需要的,如果可能的话,自动化所需资源的调度。
自动和手动优化
识别被浪费和未使用的资源(
Identify wasted and unused resources) 通过对资源使用情况的良好监控,可以很容易地找到未使用的资源或没有大量空闲时间的服务器。许多云供应商都有成本探索者,可以分解单个服务的成本。自动伸缩有助于关闭不需要的实例。合理精简(
Right-Sizing) 在开始时,选择比实际需要的功率大得多的服务器和系统可能是一个好主意。同样,良好的监控可以在一段时间内显示应用程序实际需要多少资源。这是一个持续的过程,您应该始终适应您真正需要的负载。如果你只需要它们一半的容量,就不要购买强大的机器。预留实例(
Reserved Instances) 如果你真的需要按需资源,按需定价模式是很好的。否则,你可能要为“按需”服务支付很多钱。节省大量资金的一个方法是储备资源,甚至提前支付。这是一个很好的定价模型,如果你对你需要的资源有一个很好的估计,甚至可能提前几年。竞价型实例(
Spot Instances) 如果您有一个批处理作业或在短时间内负载沉重,您可以使用现场实例来节省成本。现货实例的概念是,您可以以非常低的价格获得云供应商过度供应的未使用资源。“问题”在于,这些资源并不是为你保留的,它们可能会在短时间内被终止,供其他人“全价”使用。
所有这些方法都可以结合起来,以提高成本效益。混合按需、预留和现货实例通常没有问题。
9. 其他资源
Cloud Native Observability
Prometheus
Prometheus at scale
Logging for Containers
Right-Sizing and cost optimization
最后更新于